1. Some Important Concepts
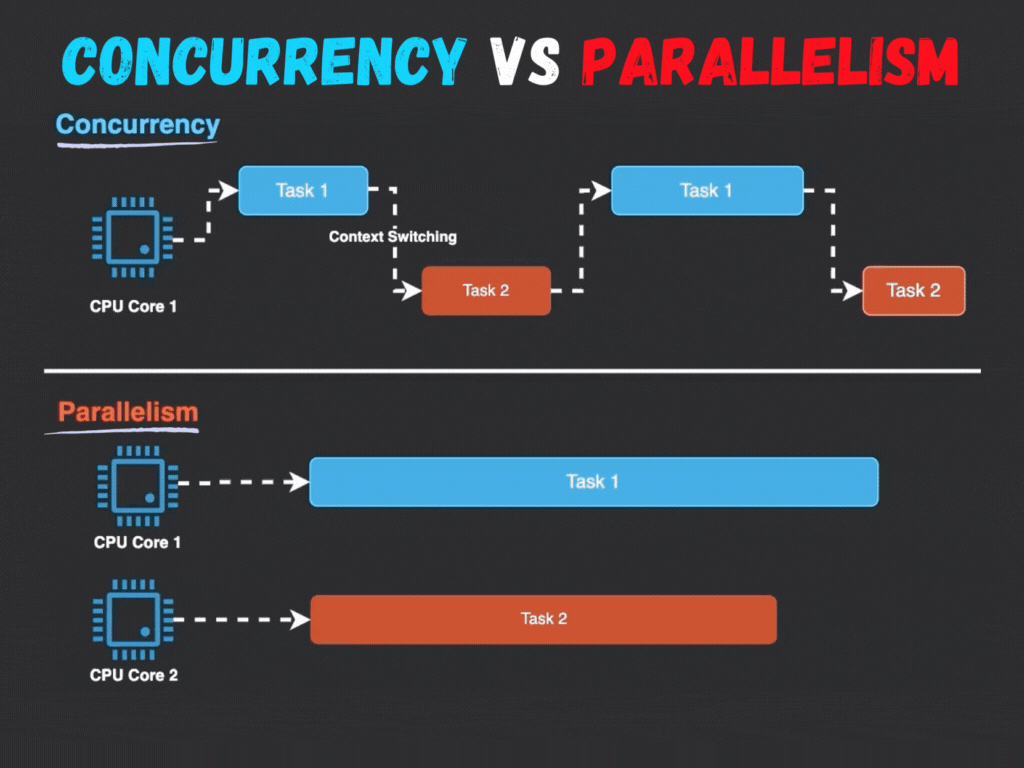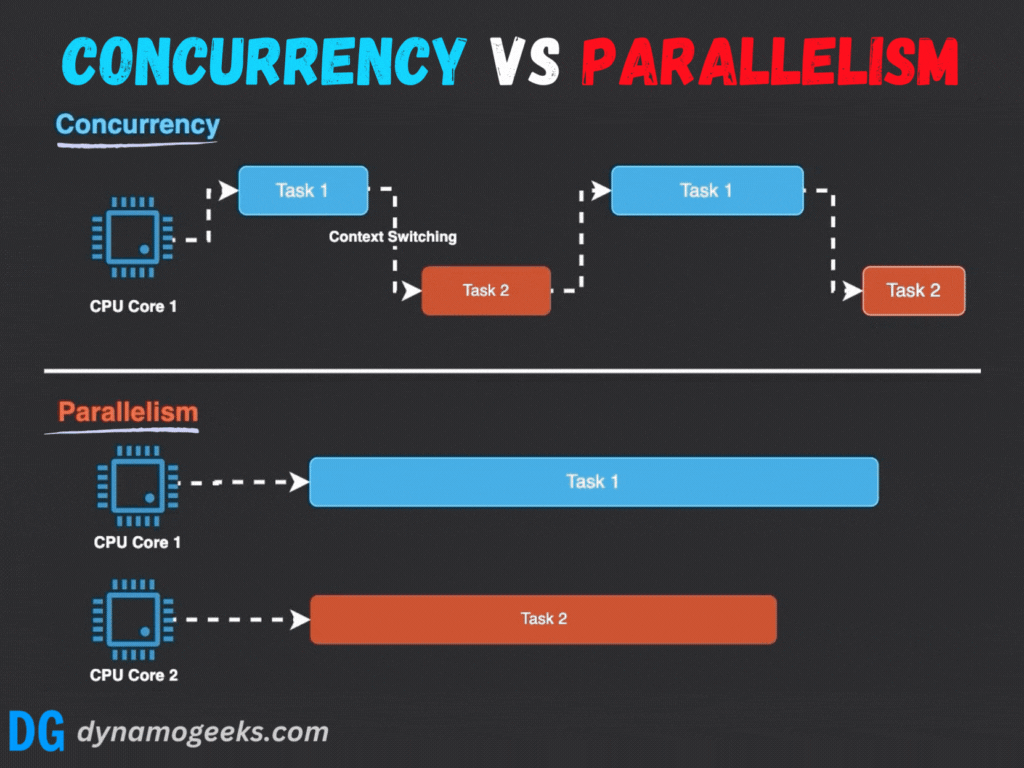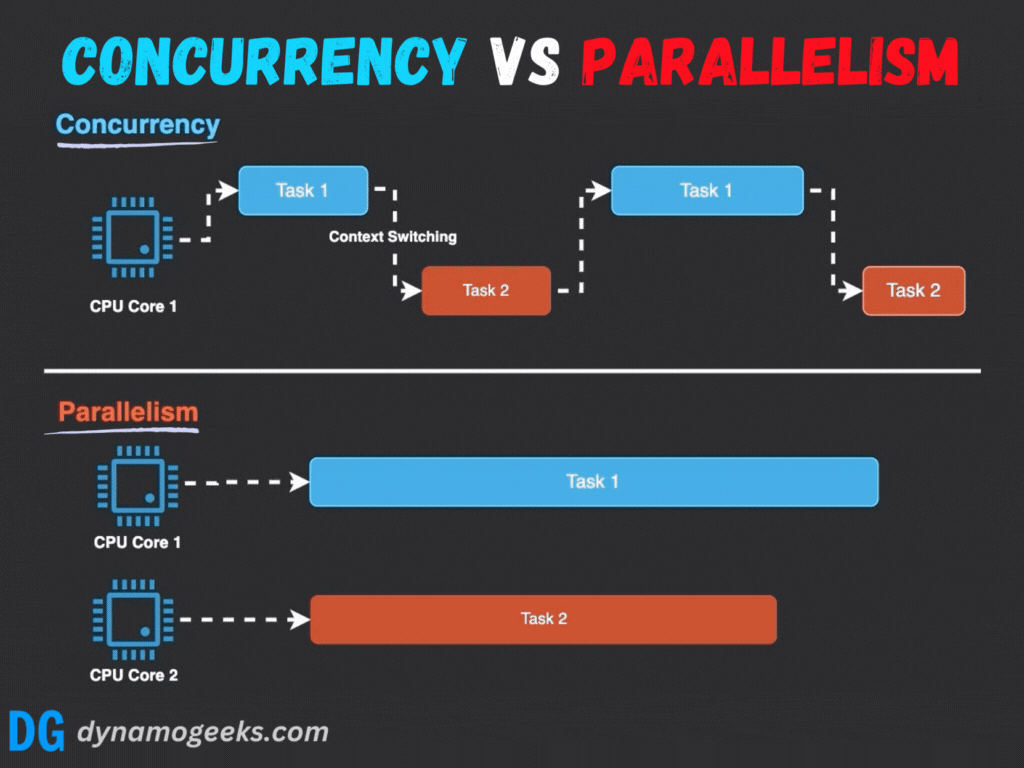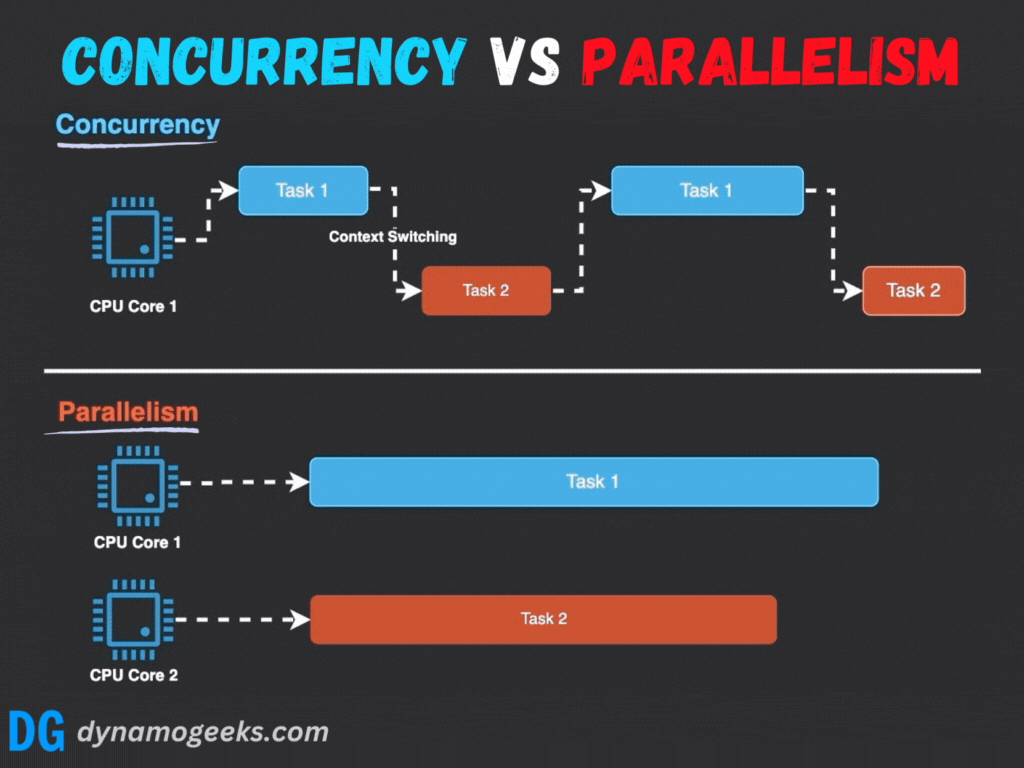
1.1 Parallism vs Concurrency
- Parallism: Running multiple tasks at the same time. There are multiple Threads or Processes running at the same time.
- Concurrency: Switching between multiple tasks. When one task is waiting for I/O, another task can run. There is only one Thread or Process running at a time.
1.2 Synchronous vs Asynchronous
- Synchronous: Code is executed in sequence. Previous task/line must be completed before the next task/line execution starts.
- Asynchronous: Code is executed in parallel. Tasks can run concurrently. The next task can start before the previous task is completed.
1.3 Blocking vs Non-Blocking
- Blocking: The execution of the code is blocked until the task is completed. The next task can’t start until the previous task is completed.
import time
def task1():
print("Task 1 started")
time.sleep(2)
print("Task 1 completed")
def task2():
print("Task 2 started")
time.sleep(2)
print("Task 2 completed")
task1()
task2()
- Non-Blocking: The excecution of the code is not blocked. The next task can start before the previous task is completed.
import asyncio
async def task1():
print("Task 1 started")
await asyncio.sleep(2)
print("Task 1 completed")
async def task2():
print("Task 2 started")
await asyncio.sleep(2)
print("Task 2 completed")
async def main():
await asyncio.gather(task1(), task2())
asyncio.run(main())
1.4 I/O Bound vs CPU Bound
- I/O Bound: The program is waiting for input/output operations to complete. The program is not using the CPU much.
- CPU Bound: The program is using the CPU a lot. The program is not waiting for input/output operations to complete.
import request
response = request.get("https://www.google.com") # I/O Bound
items = response.headers.items() # CPU Bound
headers = [f'{key}: {header}' for key, header in items] # CPU Bound
formatted_headers = '\n'.join(headers) # CPU Bound
with open('headers.txt', 'w') as file: # I/O Bound
file.write(formatted_headers) # I/O Bound
2. How Concurrency is Achieved in Os level
To better understand this, we’ll need to dive into how sockets work and, in particular, how non-blocking sockets work.
2.1 Sockets
A socket is a low-level abstraction for sending and receiving data over a network. It is the basis for how data is transferred to and from servers. Sockets support two main operations: sending bytes and receiving bytes. We write bytes to a socket, which will then get sent to a remote address, typically some type of server. Once we’ve sent those bytes, we wait for the server to write its response back to our socket. Once these bytes have been sent back to our socket, we can then read the result.
In the case of getting the contents from example.com as we saw earlier, we open a socket that connects to example.com’s server. We then write a request to get the contents to that socket and wait for the server to reply with the result: in this case, the HTML of the web page. We can visualize the flow of bytes to and from the server in figure 1.7

Sockets are blocking by default. Simply put, this means that when we are waiting for a server to reply with data, we halt our application or block it until we get data to read. Thus, our application stops running any other tasks until we get data from the server, an error happens, or there is a timeout. At the operating system level, we don’t need to do this blocking. Sockets can operate in non-blocking mode. In non-blocking mode, when we write bytes to a socket, we can just fire and forget the write or read, and our application can go on to perform other tasks. Later, we can have the operating system tell us that we received bytes and deal with it at that time. This lets the application do any number of things while we wait for bytes to come back to us. Instead of blocking and waiting for data to come to us, we become more reactive, letting the operating system inform us when there is data for us to act on. In the background, this is performed by a few different event notification systems, depending on which operating system we’re running. asyncio is abstracted enough that it switches between the different notification systems, depending on which one our operating system supports. The following are the event notification systems used by specific operating systems:
- kqueue—FreeBSD and MacOS
- epoll—Linux
- IOCP (I/O completion port)—Windows
These systems keep track of our non-blocking sockets and notify us when they are ready for us to do something with them. This notification system is the basis of how asyncio can achieve concurrency.

But how do we keep track of multiple tasks that are waiting for data to come back to them? This is where the event loop comes in.
2.2 Event Loop
The event loop is the core of every asyncio application. In asyncio, the event loop keeps a queue of tasks.
2.2.1 How the Event Loop Works
- The event loop works by keeping a queue of tasks instead of messages. Each task is a coroutine.
- When a task is added to the event loop, it will execute until it encounters an I/O operation (such as a web request).
- When a task hits an I/O-bound operation, it pauses and allows the event loop to run other tasks that are not waiting for I/O operations to complete.
2.2.2 Understanding Event Loops in Asynchronous Programming
When working with event loops in asynchronous programming, the process can be understood as a sequence of steps that efficiently handle tasks without blocking the execution. Here’s a breakdown of how it works:
2.2.2.1 Creating the Event Loop
When an event loop is created, an empty queue of tasks is initialized. This queue will hold all the tasks that need to be executed.
2.2.2.2 Adding Tasks to the Queue
We add tasks to the event loop’s queue. These tasks are executed one at a time, based on their order in the queue.
2.2.2.3 Processing Tasks Iteratively
Each iteration of the event loop checks for tasks that need to be executed. It processes tasks sequentially, running them one by one.
2.2.2.4 Handling I/O Operations
If a task encounters an I/O operation (like reading from a file or making a network request), it cannot proceed immediately. In this case, the task is paused and put on hold.
2.2.2.5 Pausing and Waiting for I/O Completion
When a task is paused, the event loop instructs the operating system to monitor any associated sockets or resources for I/O completion. During this time, the event loop continues checking for and executing other tasks.
2.2.2.6 Waking Up Paused Tasks
On each iteration of the event loop, we check if any of the I/O operations have completed. If they have:
- The paused task is woken up.
- The task resumes execution and completes its process.
2.2.2.7. Conclusion
This cycle of pausing, waiting for I/O, and resuming tasks allows the event loop to run multiple tasks concurrently, making it an efficient way to handle asynchronous operations without blocking the program.
By continuously iterating and checking for completed I/O tasks, the event loop ensures that no task is left idle while waiting for I/O operations, enabling a smooth and efficient workflow.
Visualizing the Event Loop with Asynchronous Tasks
We can visualize how the event loop works with asynchronous tasks as shown in Figure 1.9: the main thread submits tasks to the event loop, which then runs them. When a task encounters an I/O operation, it pauses and allows other tasks to run. Once the I/O operation is complete, the paused task is resumed.
Example: Submitting Multiple Asynchronous Tasks
Let’s consider three tasks that each make an asynchronous web request. These tasks consist of:
- CPU-bound setup: Some code that prepares data for the web request.
- I/O-bound web request: The asynchronous part where we send the web request.
- CPU-bound post-processing: After the web request completes, we do some more CPU-intensive work.
Now, let’s submit these tasks to the event loop simultaneously. Here’s how we can write this in pseudocode:
def make_request():
cpu_bound_setup()
io_bound_web_request()
cpu_bound_postprocess()
task_one = make_request()
task_two = make_request()
task_three = make_request()

First task starts executing code, and the other two are left waiting to run. Once the CPU-bound setup work is finished in Task 1, it hits an I/O-bound operation and will pause itself to say, “I’m waiting for I/O; any other tasks waiting to run can run.” Once this happens, Task 2 can begin executing. Task 2 starts its CPU-bound code and then pauses, waiting for I/O. At this time both Task 1 and Task 2 are waiting concurrently for their network request to complete. Since Tasks 1 and 2 are both paused waiting for I/O, we start running Task 3. Now imagine once Task 3 pauses to wait for its I/O to complete, the web request for Task 1 has finished. We’re now alerted by our operating system’s event notification system that this I/O has finished. We can now resume executing Task 1 while both Task 2 and Task 3 are waiting for their I/O to finish. In figure 1.10, we show the execution flow of the pseudocode we just described. If we look at any vertical slice of this diagram, we can see that only one CPU-bound piece of work is running at any given time; however, we have up to two I/O-bound operations happening concurrently. This overlapping of waiting for I/O per each task is where the real time savings of asyncio comes in.
